昨天我們已經把 LLM 的訓練訓練跑了個大概,但也就只是跑起來還沒開始學習,今天就來細看第一步吧。
主要是以我有實作的 github 當作例子,所以比較會偏向 ASR 及 TTS,有興趣的可以看看。
核心觀念: 文字 → 數字
tokenizer (分詞器) 的想法其實很簡單,因為不管是中文字還英文字都沒辦法直接丟進去給模型做訓練,所以 tokenizer 會透過辭典將單詞轉換成"數字",轉後過後才可以當輸入送進模型,然而數字從 0 開始 (可以看從 model/tokenizer.json)。
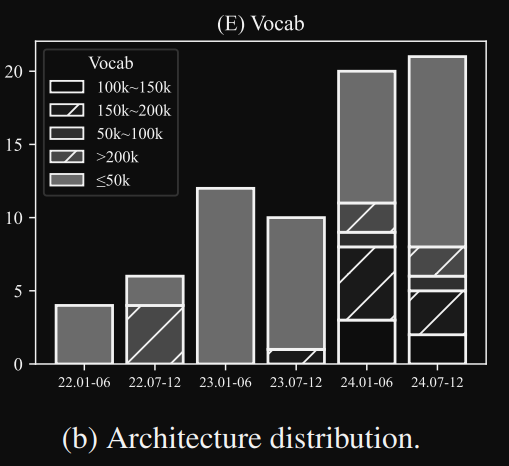
Q: 那至於現在的 LLM 辭典大小都是多少呢??
A: 我們參考這篇論文 SMALL LANGUAGE MODELS:
SURVEY, MEASUREMENTS, AND INSIGHTS (這篇論文的統計之後還會提到),當中的圖表有統計 SLM 的部分,每年的趨勢可以當作參考,畢竟辭典大小會影響到模型大小和訓練的難易度,太大不好太小也不好,所以各家模型都會有些微差異(可參考論文 Table 1)。
Q: 那在 ASR 跟 TTS 辭典又是多大呢??
A: 我們以現有的模型來看
ASR (nemo canary) 大概會是以下這樣,通常會是 512, 1024 的倍數,那中文因為是以字為單位,所以需要比較多
英, 法, 德: 1024
韓: 3072
日, 中: 8192
TTS 的部分主要是以拼音為辭典,以 MeloTTS 多個外國語言大概一兩百個,那如果以中文來說通常使用 pinyin 或 g2pW 大概落在 1550 左右( ZipVoice , F5-TTS)。
Q: 有哪些 tokenizer 的演算法呢??
A: 主要是 bpe, SentencePiece, Unigram, bbpe …
(補充: 在中文 ASR 採用 bbpe 效果更好,可參考這篇講解)
以 scripts/train_tokenizer.py 當中其實就是用 tokenizers 這個 package 來訓練,基本上就幾行程式而已,這邊就不過多敘述,稍微補充幾種 special_tokens。
# 定義特殊token, 基本上可以定義你想要的
# 多模態的
# https://huggingface.co/microsoft/Phi-4-multimodal-instruct/blob/main/tokenizer_config.json
# 如果是多語言 asr 會有 language tag
# https://huggingface.co/openai/whisper-large-v3/raw/main/tokenizer_config.json
# 如果是 ASR + LLM
# https://huggingface.co/VITA-MLLM/VITA-Audio-Boost/raw/main/tokenizer_config.json (拉到最底)
special_tokens = ["<|endoftext|>", "<|im_start|>", "<|im_end|>"]
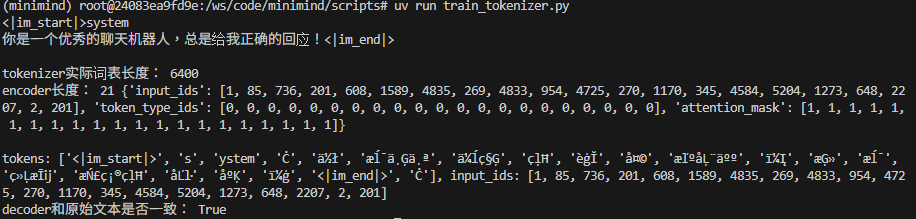
我們先簡單認識一下分詞完的結果長怎樣,後面會有詳細介紹
我們在 scripts/train_tokenizer.py 修改一下程式,打印一下輸出,那因為是用 ByteLevel,所以中文字會是看不懂的符號,那英文 system → [s, ystem]
def eval_tokenizer():
from transformers import AutoTokenizer
# 加载预训练的tokenizer
tokenizer = AutoTokenizer.from_pretrained("../model/")
messages = [
{"role": "system", "content": "你是一个优秀的聊天机器人,总是给我正确的回应!"},
# {"role": "user", "content": '你来自哪里?'},
# {"role": "assistant", "content": '我来自地球'}
]
new_prompt = tokenizer.apply_chat_template(
messages,
tokenize=False
)
print(new_prompt)
# 获取实际词汇表长度(包括特殊符号)
actual_vocab_size = len(tokenizer)
print('tokenizer实际词表长度:', actual_vocab_size)
# model_inputs 會回傳 input_ids, token_type_ids, attention_mask
model_inputs = tokenizer(new_prompt)
# 其中 input_ids 是已經轉成數字格式
# 我們可以透過 .tokenize 看到分詞結果
# 再透過 convert_tokens_to_ids 看到原先的 input_ids
tokens = tokenizer.tokenize(new_prompt)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print('encoder长度:', len(model_inputs['input_ids']), model_inputs)
print(f'\ntokens: {tokens}, input_ids: {input_ids}')
input_ids = model_inputs['input_ids']
response = tokenizer.decode(input_ids, skip_special_tokens=False)
print('decoder和原始文本是否一致:', response == new_prompt)
def main():
# train_tokenizer()
eval_tokenizer()
參考文章: https://zhuanlan.zhihu.com/p/652520262 ,參考文章當中寫得非常詳細,底下只是做些總結及整理。
依照精細程度分成: 詞 word-based < 子詞 subword-based < 字符 character-based
以下舉個例子就可以明白
| word-based | char-based | subwrd-based | ||
|---|---|---|---|---|
| 中文 | 我喜歡看電影 | 我 | 喜歡 | 看 | 電影 | 我 | 喜 | 歡 | 看 | 電 | 影 | X |
| 英文 | Let us learn tokenization. | [“Let”, “us”, “learn”, “tokenization.”] | [“L”, “e”, “t”, “u”, “s”, “l”, “e”, “a”, “r”, “n”, “t”, “o”, “k”, “e”, “n”, “i”, “z”, “a”, “t”, “i”, “o”, “n”, “.”] | [“Let”, “us”, “learn”, “token”, “ization.”] |
| 優點 | 1. 語義明確 2. 上下文理解 | 1. 簡單暴力,各語言處理方式一樣 2. 不會有 OOV 問題 | 1. 兼具前兩種優點 | |
| 缺點 | 1. 辭典要很大, 但一定會有漏掉的詞,就會產生 OOV(Out-of-Vocabulary) 2. 限制模型的理解能力,比如 learn 和 learning 在辭典會是兩個詞 | 1. 英文語義不明確 2. 效率差記憶體大,因為每個 token 都需要 memory,所以越多 token 效率越差記憶體大計算量大。 | 1. 但中文沒辦法用 (所以才有 bbpe 針對中文這種) |
這裡整理參考文章的 code,我自己也是跟著寫一遍
核心觀念: 單詞 → 多個前綴符號(類似 bert 中的 ##) → 慢慢合併成子詞
舉例來說: tokenization→ t ##o ##k ##e … → token #ization
會有以下步驟(來至於參考文章):

def WordPiece(sentences, vocab_size = 50):
# Step 1: 計算初始詞表
# Step 1.1: 計算詞頻
stats = build_stats(sentences)
# Step 1.2 建立初始詞表
#['##a', '##e', '##g', '##h', ..., 'I', 'S', ..., '不', '他', '吃', '喜', '我', '苹']
vocab = build_init_alphabet(stats)
# splits: {'我': ['我'], '喜欢': ['喜', '##欢'], ...
splits = split_stats(stats)
while len(vocab) < vocab_size:
# Step 2: 計算合併分數
pair_scores = compute_pair_scores(stats, splits)
# Step 3.1: 找到最高的分數
best_pair, max_score = "", None
for pair, score in pair_scores.items():
if max_score is None or max_score < score:
best_pair = pair
max_score = score
# step 3.2: 合併分數最高的子詞對
splits = merge_pair(*best_pair, stats, splits)
# step 3.3: 更新詞表
new_token = (
best_pair[0] + best_pair[1][2:]
if best_pair[1].startswith("##")
else best_pair[0] + best_pair[1]
)
vocab.append(new_token)
return vocab
def main():
sentences = [
"我",
"喜欢",
"吃",
"苹果",
"他",
"不",
"喜欢",
"吃",
"苹果派",
"I like to eat apples",
"She has a cute cat",
"you are very cute",
"give you a hug",
]
vocab = WordPiece(sentences, vocab_size = 50)
print(vocab)
if __name__ == "__main__":
main()
build_stats: 用 dict 來存放次數的統計
from collections import defaultdict
# stats: defaultdict(<class 'int'>, {'我': 1, '喜欢': 2, '吃': 2, '苹果': 1, '他': 1, '不': 1, '苹果派': 1,
# 'I': 1, 'like': 1, 'to': 1, 'eat': 1, 'apples': 1, 'She': 1, 'has': 1, 'a': 2, 'cute': 2, 'cat': 1, 'you': 2, 'are': 1, 'very': 1, 'give': 1, 'hug': 1})
def build_stats(sentences):
stats = defaultdict(int)
for sent in sentences:
# 英文用空格切成單個詞
# 中文事先斷詞 -> 否則可用 jieba, ckip
words = sent.split()
for word in words:
stats[word] += 1
return stats
build_init_alphabet: ##是個特殊符號,代表是從詞拆出來的中間或尾部 (ex: 喜歡 → 喜, ##歡)
#['##a', '##e', '##g', '##h', ..., 'I', 'S', ..., '不', '他', '吃', '喜', '我', '苹']
def build_init_alphabet(stats):
alphabet = []
for word in stats.keys():
if word[0] not in alphabet:
alphabet.append(word[0])
for letter in word[1: ]:
if f"##{letter}" not in alphabet:
alphabet.append(f'##{letter}')
alphabet.sort()
return alphabet
split_stats: 將原本統計的詞頻,建立每個詞的初始分割
# splits: {'我': ['我'], '喜欢': ['喜', '##欢'], ...
def split_stats(stats):
splits = {
word: [c if i == 0 else f"##{c}" for i, c in enumerate(word)]
for word in stats.keys()
}
# 上面是將 for 合成一行相當於下面
# splits = {}
# for word in stats.keys():
# temp = []
# for i, c in enumerate(word):
# if i == 0:
# temp.append(c)
# else:
# temp.append(f'##{c}')
# splits[word] = temp
return splits
compute_pair_scores: 統計所有 pair 的出現頻率與分數
def compute_pair_scores(stats, splits):
letter_freqs = defaultdict(int)
pair_freqs = defaultdict(int)
for word, freq in stats.items():
split = splits[word]
if len(split) == 1:
letter_freqs[split[0]] += freq
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
letter_freqs[split[i]] += freq
pair_freqs[pair] += freq
letter_freqs[split[-1]] += freq
scores = {
pair: freq / (letter_freqs[pair[0]] * letter_freqs[pair[1]])
for pair, freq in pair_freqs.items()
}
return scores
merge_pair: 選出分數最高的 pair 進行合併
def merge_pair(a, b, stats, splits):
for word in stats:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
merge = a + b[2:] if b.startswith("##") else a + b
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
因為不希望篇幅太長,這邊就以 WordPiece 為實作,有興趣可以再完成 bpe 的部分,本系列會參考大量的文章,文章內容寫的都很不錯,如果想更進一步可以看看,或者參考我整理過後的版本,目的是希望你不要被這篇文章侷限,而是應該要多看多學。
今天就介紹到這囉 ~~


 iThome鐵人賽
iThome鐵人賽